更新:
有同学反馈说:网络效率的函数可能有点问题。可以试试这个网络效率函数 ,对应的部分改一下就可以了。
还有最大连通子图比例函数:最大连通子图比例函数
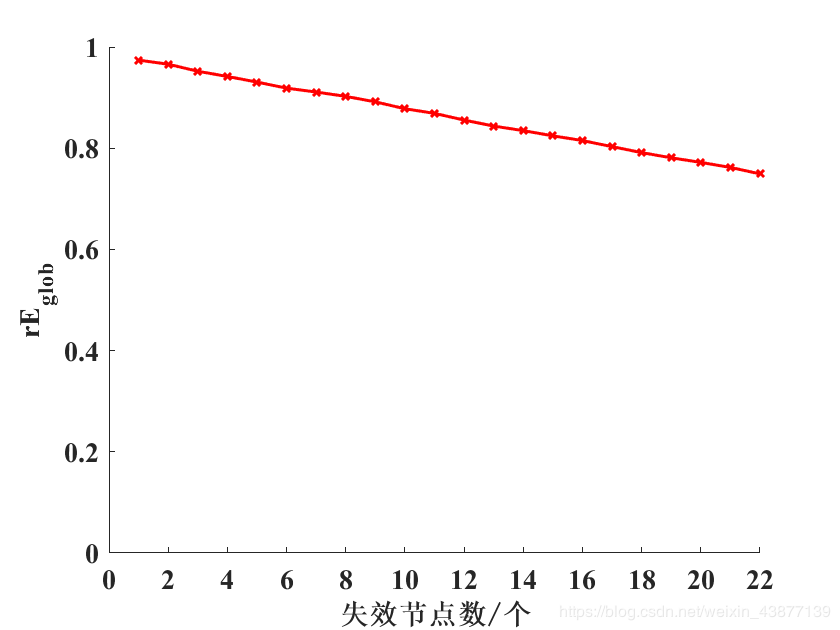
在研究网络的鲁棒性的时候,我们往往会通过随机与蓄意攻击网络节点,观察网络效率的下降比例来进行网络特性的研究。
常见的指标有:最大连通子图比例、网络效率、平均距离 等等。原理是相同的 ,这里以按照节点度 攻击的网络效率 变化为例(其他两个指标就是函数不同,想按照其他节点重要度排序指标,也是类似的,只需要按照想要的排序方法得出节点的排序即可)。
就是按照节点的重要性排序,通过循环来删除节点。把临界矩阵中节点对应的行和列先置0,然后再删除。每删除一次节点,就生成了一个新的邻接矩阵,然后每一次都通过testEglob函数计算出当前的网络效率值。
首先需要准备的数据如下:
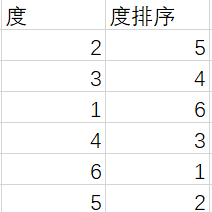
网络的邻接矩阵,节点度的排序(从大到小排名,度大的排名靠前)。
节点度的排名要按照节点的编号排序,下图是一个简单的例子,建议先在Excel中排列好了,然后再复制到Matlab中转置一下保存为mat文件就可以了。
明白了蓄意攻击的原理,那么随机攻击的原理也比较好理解了,蓄意攻击是按照节点重要度排序进行的攻击,那么随机攻击可以理解为给所有节点随机赋排名,所以攻击的时候就等效于随机攻击了。也就是说,在随机攻击时,你只需要在蓄意攻击的基础上添加一行代码,把度排序的数组赋值上长度相同的一个随机数组,即:
1 Name_Struct.Node_Key_Degree = randperm(440);
具体代码如下:
主函数: testRandom(命名随意。。。)作用:原理挺简单的,就是通过循环来删除节点。把临界矩阵中节点对应的行和列先置0,然后再删除。每删除一次节点,就生成了一个新的邻接矩阵,然后每一次都通过testEglob函数计算出当前的网络效率值。
部分代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 clc; clear; Name_Struct.Node_Key_Degree = randperm(440 ); A = A_Init; B=[]; for i = 1 :NumDelete B(i ) = Name_Struct.Node_Key_Degree(i ); Con_Index_NetEff = testEglob( AA ); Eglob(i ) = Con_Index_NetEff.Net_Eff_Mymod; end
正常情况下,一次随机攻击 并不能说明什么,一次随机攻击的数据也并不可靠,所以需要多次随机攻击之后取平均值 ,这样得出的数据才更具有说服力,下一篇将介绍如何实现,matlab实现随机攻击网络节点+蓄意攻击网络节点(2)
希望对大家有所帮助,有任何疑问欢迎与我交流,谢谢你的时间。

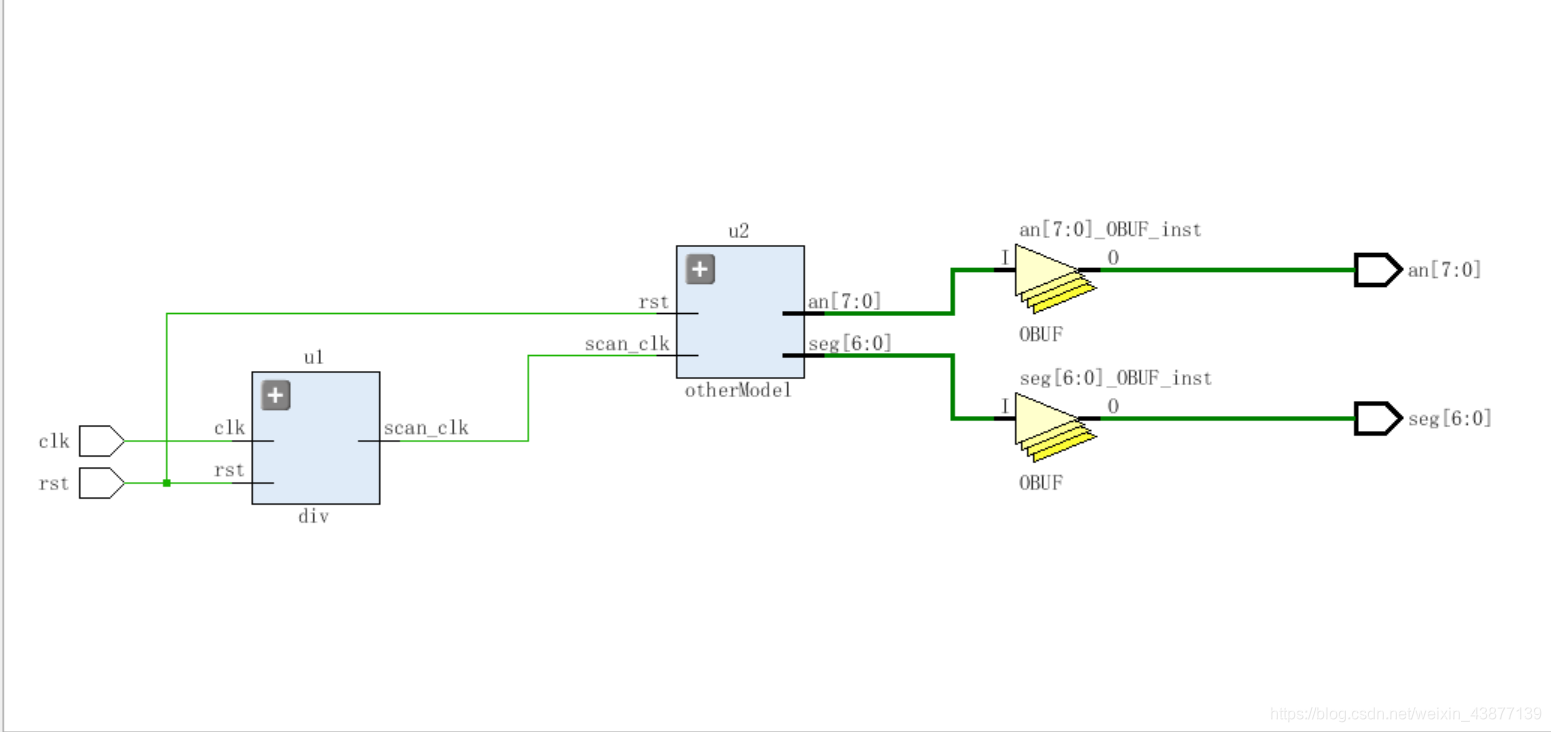
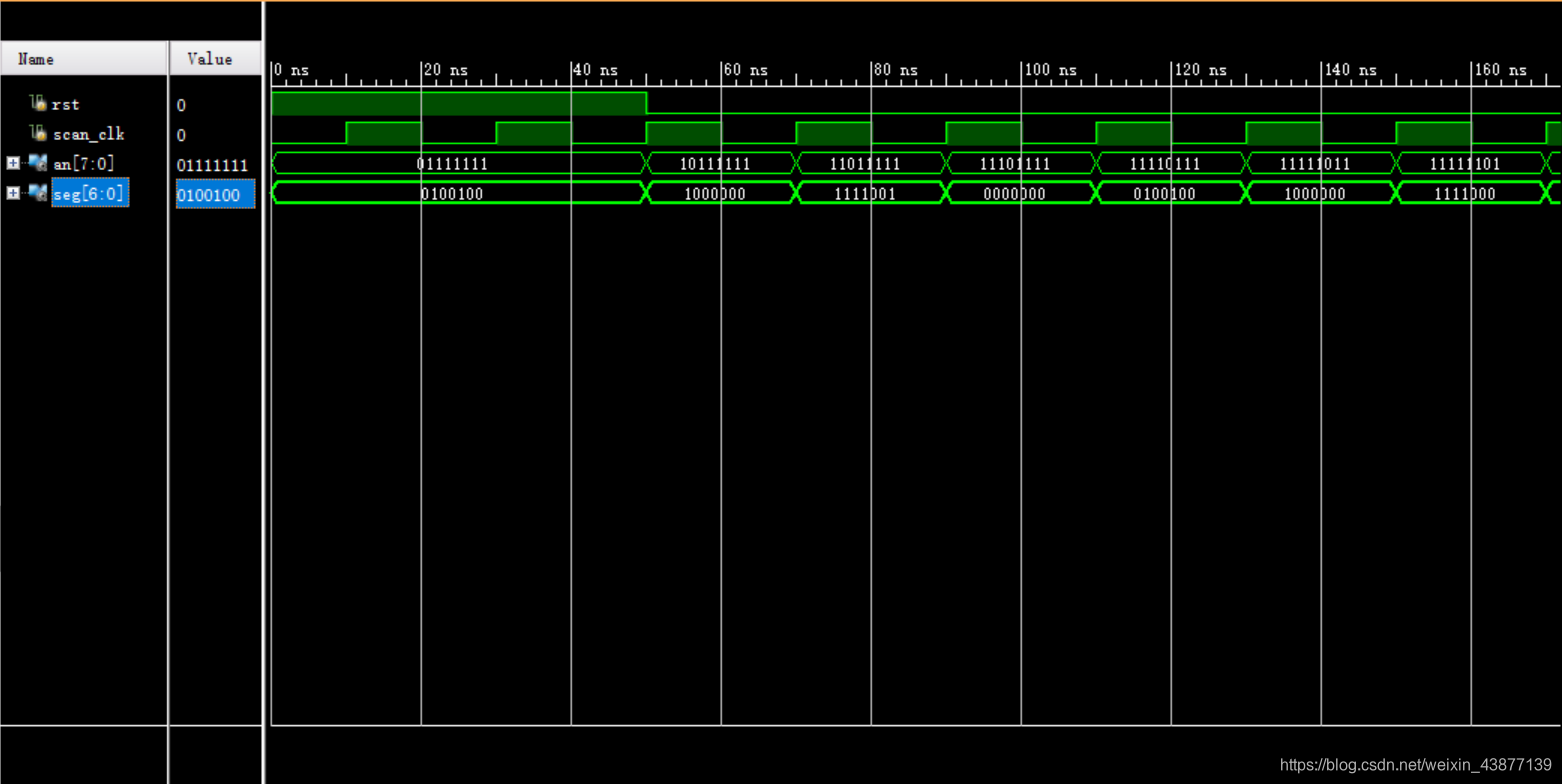












 同理可以改成任意进制,或者是可以改成减计数。
同理可以改成任意进制,或者是可以改成减计数。